Coordinating a multi-lambda software product
29th August 2021Introduction
The more I have been working on AWS, the more I understanding the importance of well-architected solutions. Today, I would like to focus on the value of AWS Step Functions. What are Step Functions? The offical description is:
AWS Step Functions is a low-code visual workflow service used to orchestrate AWS services, automate business processes, and build serverless applications. Workflows manage failures, retries, parallelization, service integrations, and observability so developers can focus on higher-value business logic.
To explain the value, I am going to use some hypothetical use cases, which are:
- Use Case One: As a GitHub administrator, whenever a new developer joins the GitHub organisation, I would like to add them to a GitHub Team so that they can access repositories straight away. I also would like to fetch internal company information about that user (email, id, etc.) and add them to an internal DB for querying.
- Use Case Two: As a GitHub administrator, whenever a GitHub Workflow completes, I would like to calculate the workflow cost and work out the total workflow count for the repository, so it's easy to do chargebacks per repository. I also would like to store the data in a DB so it can be queried historically.
Before we build out some architectures, let's set some principles:
- Purposeful: Single function lambda's for single-use cases. (not combining multiple businesslogic into a single lambda). This is to promote reuse.
- Event Driven: No polling or waiting on a cron which triggers to see if things have changed. I would like an end-to-end event driven architecture.
- Stateful: Non-Invoke Based (Callback hell). E.G Lambda A Invoked Lambda B from within Lambda A and waits for Lambda B to be done to return success/fail
Now, as with any architecture, there are multiple ways to build out this example system. I will show two examples below and compare & contrast the pros and cons of each, mainly focusing on how to use multiple lambdas together and why AWS Step Functions are beneficial.
Model One - SQS
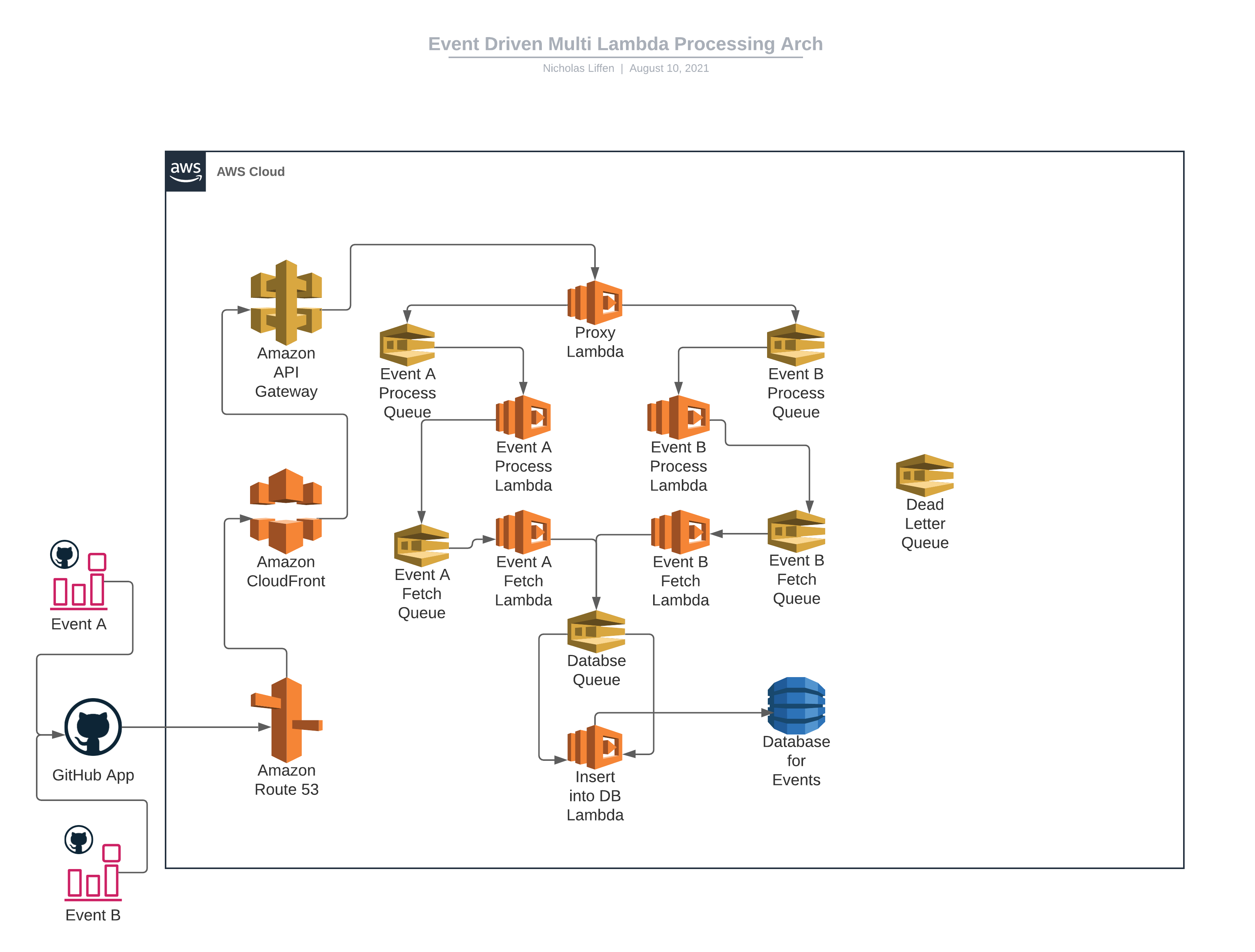
Let's walk through the above diagram. We have a GitHub App configured on two events (A, B). We use a GitHub App to remove the "human" element of the connection, along with some other goodies like an increase in API Requests. The GitHub App will send a payload to our API, but before it reached the API, we use AWS Route 53 for our custom DNS record, which then will proxy down to our AWS Cloudfront Distribution.
Once the payload reaches the API, we will first use the direct integration between AWS HTTP API Gateways and AWS Lambda to first process the data. Then, to communicate between the rest of the lambdas, we use AWS SQS to traffic data between lambdas for processing. Finally, data ends up in the database where you could use a service like AWS AppSync or another API Gateway to fetch the data.
Let's talk about the pros:
- Extensible: It's extensible, as an individual SQS Queue fronts each function. Meaning, you're able to quickly send data to that function from any service that can send structured data. You may know about Lambda X needing to send data to Lambda Y. Still when a new Lambda comes in, Lambda Z, it's easy to add that lambda into the current architecture and send data to Lambda Y without breaking the current pattern.
Let's talk about the cons:
- Clean Arch: It's a little messy. I am a big believer that most clean architectures are simple. Don't overcomplicate something and add AWS services because it could fit a need. Look at alternatives to reduce your footprint. There are 6 SQS Queues; they seem to be the most predominant service in this design. Are they needed?
- Problem Finding: How easy is it to really find problems? We have a dead letter queue configured so any messages that don't complete can be re-processed accordingly, but you only see a problem at a time; you don't see the history of where that data has come from or where it has been or how it has been processed. You would have to write some custom code to do this.
- App Tracking: Amazon SQS requires you to implement application-level tracking, especially if your application uses multiple queues, which in this case, it does.
Overall, this isn't a bad architecture, it fits a use case, but could it be fine-tuned?
Model Two - Step Functions
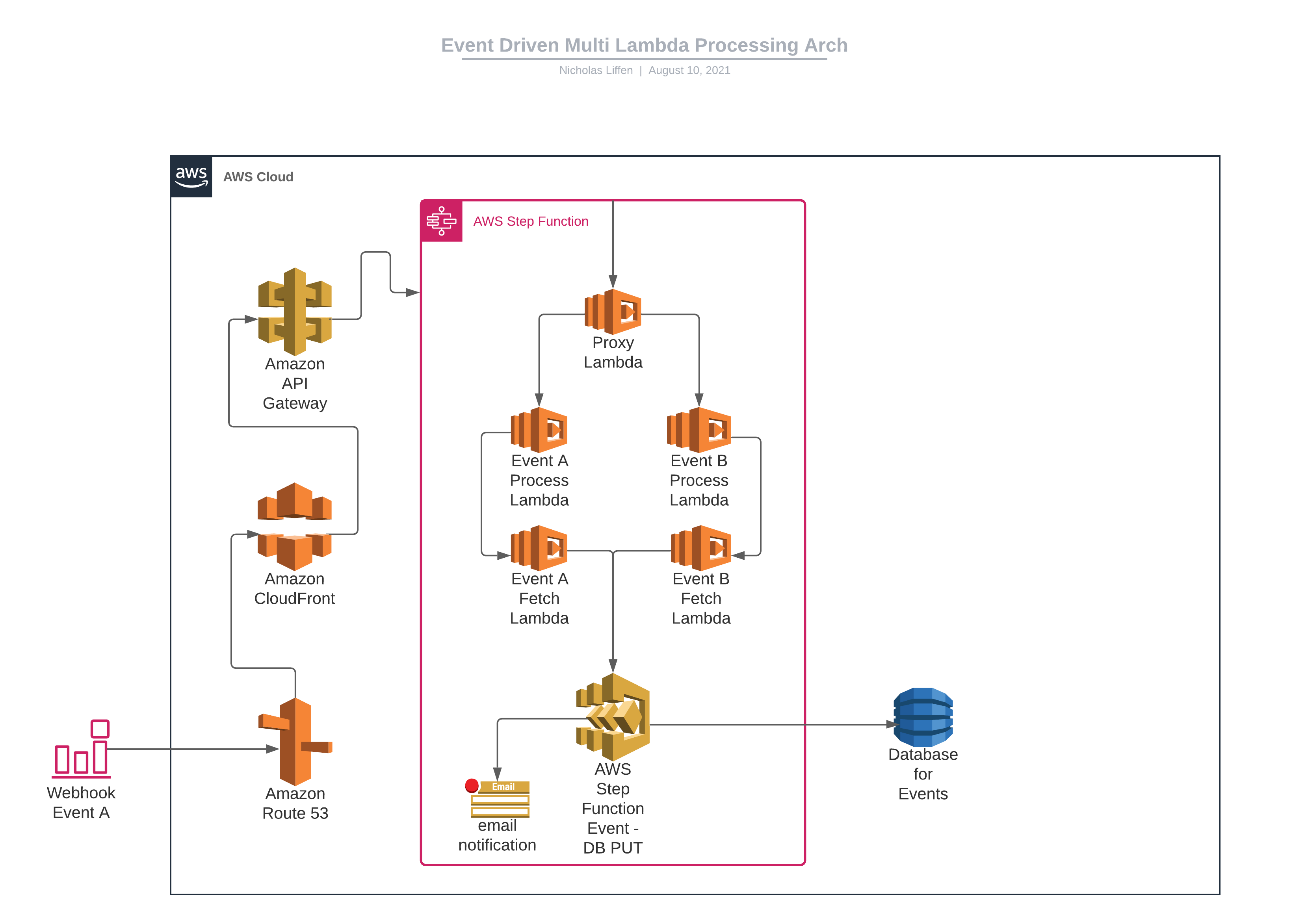
Both ingress patterns into AWS are the same. The main difference starts when you get past the AWS HTTP API Gateway and into the data processing.
As this solution has multiple lambdas, we use AWS Step Functions to coordinate how they interact. So, when a payload reaches the HTTP API, we trigger the AWS Step function. Data is processed by each lambda and sent back to the state machine, where finally it inserts data into the DB and uses a custom AWS SNS Topic to send an email on success/error.
Both have similar architectures but differ slightly in data communication; let's discuss the detail ...
Let's talk about the pros:
- Less Code: We don't have to write a custom lambda to enter data into the DB. Step functions have a native integration with DynamoDB, meaning we don't have to write code to do something preexisting. More information on integrations can be found here: Using AWS Step Functions with other services.
- Less AWS Resource(s): No need for any queues. We use the state machine to send data to the following lambda in the chain. More information on how to send data within step functions can be found here: State Machine Data
- Process Overview: Easy to see the whole process in action. Step Functions easy allow you to see the data that is processing. To see more information on seeing the overall process, check out this link: Input and Output Processing in Step Functions
- Easy to find problems: Don't you dislike having to crawl through cloudwatch events to find errors logged out from a lambdas console? Using AWS Step Functions allows you to quickly find errors via the Step Functions GUI as you can crawl through the state machines events to find problems. I find this link really useful for more information on debugging: Monitoring & Logging
- Built in retries: Sometimes lambdas error and writes into DynamoDB's fail. Although they are rare, if not handled correctly, they could cause downstream dilemmas. Step Functions have inbuilt retry capabilities that allow you to retry on specific errors. Meaning you can only retry on specific event errors that you would like to retry on. More information on this can be found here: Monitoring & Logging
Let's talk about the cons:
- Con One: Step Functions has some pretty strict and small limits (I actually think this article is a nice summary of the limits: Think Twice Before Using Step Functions — Check the AWS Serverless Service Quotas). If you are processing lots of data, you would need to split your step functions into multiple state machines. One idea on how to architect your solution around this limit is to create a parent/child sate machine. E.G, a child state machine could process a single data entry at a time, which invokes from a parent state machine that loops through the data, but doesn't directly do any of the processing, so it stays within limits.
- Con Two: If another system needs to reuse a specific function, there is no queue in front of it, making it harder to call. Making the architecture not amazingly extensible. Yes, you can still use AWS SQS with step functions, but unless you think it's needed externally to this use case, it likely isn't required.
Overall, I genuinely believe this architecture is cleaner and runs a more robust process than the previous design.
Going into detail about Step Functions
I would like to focus on two core parts of step functions that stand out to me:
Feature One: Built in looping through arrays
Let's say you have a data set of 1,000 users. You could send all 1,000 users to the lambda via an SQS Queue (but you can only send ten records at a time, remember), loop through all users, process them accordingly and send them back to the state machine. Or, you could use the inbuilt map feature within Step Functions that will map through the user's array at the sate machine level and send one user record at a time to the lambda for processing. Why would you do this? It allows you to write less code within your lambda, fewer loops, hopefully, quicker processing. In my opinion, it also makes your code cleaner.
It looks a little like this within the state machine definition file:
Invoke Worker State Machine:
Type: Map
InputPath: "$.users"
MaxConcurrency: 50
Parameters:
UserDetails.$: "$$.Map.Item.Value"
Feature Two: AWS Step Functions can call AWS Step Functions
As mentioned above, AWS Step Functions have some pretty strict (and small) limits. Meaning you have to architect your solutions correctly. An elegant aspect of Step Functions is they can call other step functions. Meaning if you have been processing lots of data and are reaching limits, you can split up your Step Function into one parent step function, and then a child step function where you send one data record at a time to be processed individually from the parent.
It looks a little like this within the state machine definition file:
Iterator:
StartAt: Invoke Worker State Machine Task
States:
Invoke Worker State Machine Task:
Type: Task
Resource: arn:aws:states:::states:startExecution.sync:2
Parameters:
StateMachineArn: "${ChildStateMachineArn}"
Input:
UserDetails.$: "$.UserDetails"
AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$: "$$.Ex.Id"
Taking the above two code snippets, you are looping through the user's array of objects and sending one user at a time. Let's say you have 1,000 users; you are spinning up 1,000 child step functions and processing one user at a time.
These are just two features that I think make Step Functions a great resource to use when co-ordinating a multi-lambda solution. However, there are so many more, check out the docs here for more information.
Conclusion
I have found Step Functions to be a great resource when working across lambdas. They give you more confidence in your design and allow you to write less code, and in most cases, less code is better code, right?